蘋果機器學習研究中心於6日發表最新研究論文,質疑當前大型推理模型(LRMs)真正具備推理與思考能力。研究指出,這些AI模型實際上依賴的是模式匹配與記憶,而非真正邏輯推理。
研究團隊對包括OpenAI o3-mini、DeepSeek-R1、Anthropic Claude 3.7 Sonnet Thinking及Google Gemini Thinking等前沿模型進行評估,發現它們在中等複雜度任務中表現良好,但一旦任務複雜度超過臨界點,準確率會驟降至零。研究還指出,模型在高難度任務中反而使用更少token進行思考,顯示出推理機制的根本性瓶頸。
論文《思考的幻象》指出,傳統評估方法過度依賴數學與編程基準,忽略內部推理過程與潛在數據污染問題。研究人員採用可控解謎環境分析模型的推理軌跡,發現即便是具備思考鏈生成能力的模型,也無法在高複雜度下穩定運行。
研究建議,未來應採用更細緻的實驗設計,以全面理解語言模型推理的本質與侷限。
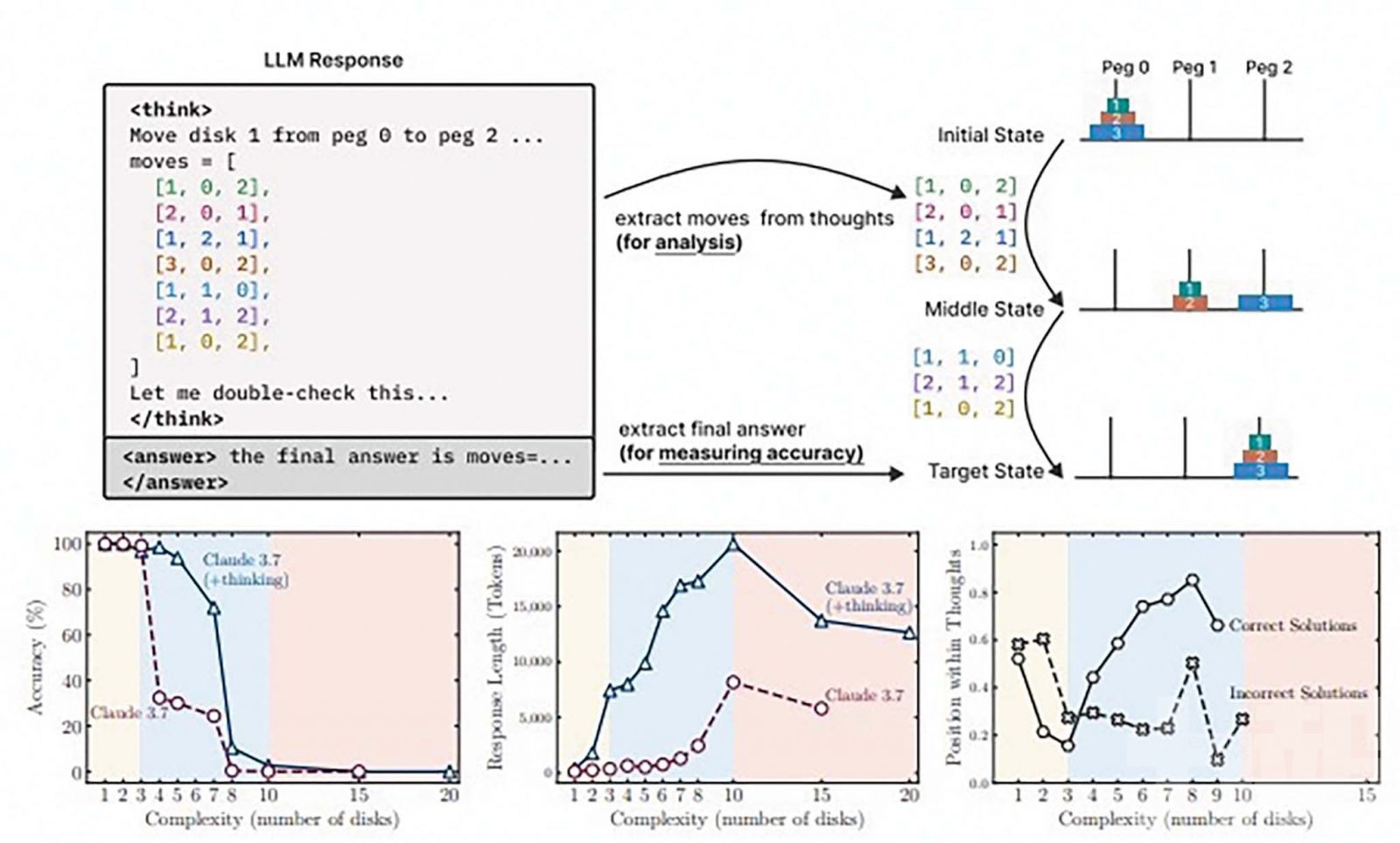
蘋果機器學習研究中心公布最新研究,質疑AI的推理能力。(網絡圖片)

















